
Multimodal Search
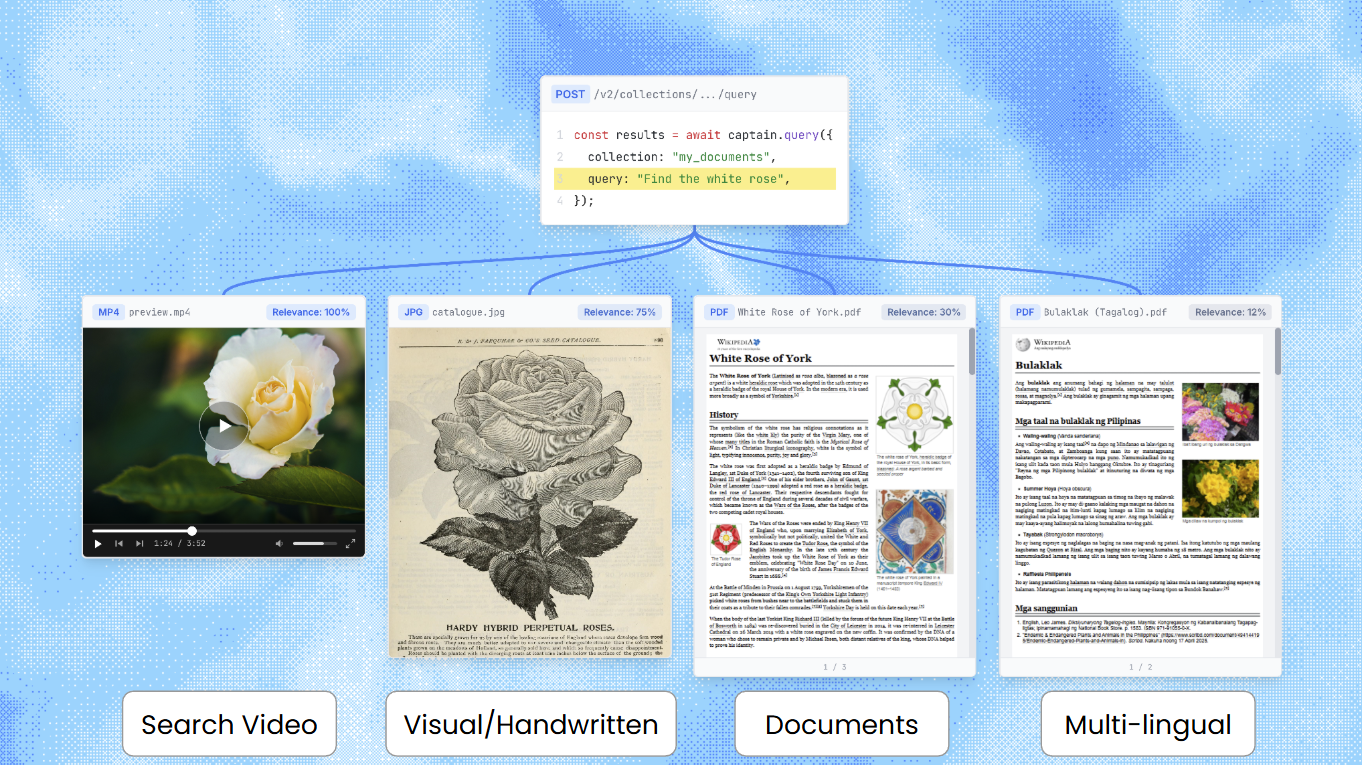
Captain supports native multimodal search across text documents, images, video, and audio files. Upload any combination of file types to a single collection, and search across all of them with one query. Captain handles format detection, media segmentation, embedding, and cross-modal ranking automatically.
Benchmark Results
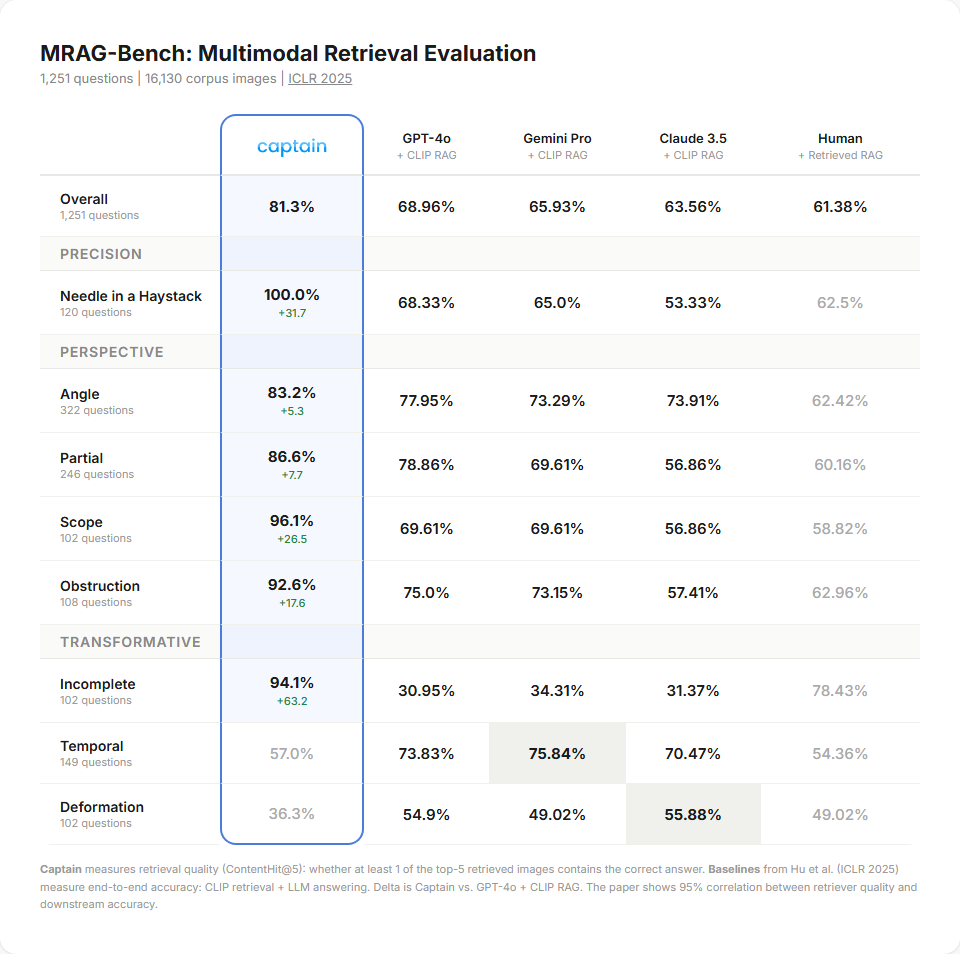
On MRAG-Bench (ICLR 2025), a standardized academic benchmark for vision-centric retrieval with 16,130 images and 1,251 questions, Captain achieves 81.3% retrieval accuracy-outperforming every end-to-end RAG system tested in the paper, including GPT-4o with CLIP retrieval (68.96%). Full results, methodology, and evaluation code are available in our open-source evaluation repository.
Supported File Types
How It Works
Captain uses a dual embedding strategy for media files. Each image, video segment, or audio segment is embedded in two ways:
-
Native multimodal embedding (3072 dimensions): The raw bytes-image pixels, audio waveform, video frames-are embedded directly. This captures the actual visual, auditory, or temporal content.
-
Text embedding (1024 dimensions): A model generates a structured description of what the media actually contains (a transcript for audio, a visual description for images and video), and that text is embedded alongside your text documents. Your query matches the content of the media, not just its filename.
This dual approach means a query for a song finds audio files both by matching the sound of the music (native embedding) and by matching the transcribed lyrics (text embedding). A search for the line “uptown funk you up” surfaces the right track even when the file is named track03.mp3.
Why reranking is required
Relevance scores from text search and media search are produced by different models on different scales. A text reranker score of 0.7 and a media cosine similarity of 0.7 do not mean the same thing and cannot be sorted into a single list.
Captain solves this with reranker-informed pipeline weighting: the text reranker’s scores on media descriptions are used to determine how much weight each modality should receive in the final ranking. This is why rerank=true is required for multimodal collections-without the reranker, there’s no way to produce a meaningful cross-modal ranking.
Text-only collections
If your collection contains only text documents, multimodal search adds zero overhead. Captain automatically detects whether a collection has media content and skips the multimodal pipeline entirely for text-only collections.
Querying Multimodal Collections
Reranking is required when a collection contains multimodal content (images, video, or audio). If you set rerank=false on a multimodal collection, the query fails. Text-only collections work with rerank=false as before.
Example: Multimodal Search
Response:
Request Fields
Response Fields (per search result)
Media label format
There are no separate start/end timestamp fields on a result. For media, the segment label
is the prefix of the content string, followed by a newline and the VLM description. The exact
formats are:
<start>/<end> are whole seconds. To extract them, parse the bracketed prefix of content
(e.g. regex ^\[Video: (.+), (\d+)s-(\d+)s\]). The text after the first newline is the
searchable description.
If you query a multimodal collection with rerank=false, the request fails:
Status code: 500 Internal Server Error
This error only occurs for collections that contain media files. Always send rerank=true for multimodal collections. Text-only collections work with rerank=false as before.
Indexing Media Files
Media files are indexed through the same endpoints as text documents. No special configuration is needed-Captain automatically detects the file type and routes it through the appropriate processing pipeline.
Index from cloud storage
Index from URL
Upload files directly
Using with Inference (AI-Powered Answers)
When inference=true, the AI agent automatically searches across all content types. Media results are presented to the agent as text descriptions with timestamps, and the agent can cite specific media files and segments in its response.
The agent sees media results as text labels like [Video: meeting_recording.mp4, 32s-120s] followed by the VLM-generated description, allowing it to cite specific timestamps in its response.
Limitations
- Video segments: Maximum 120 seconds per segment. Longer videos are automatically split.
- Audio segments: Maximum 80 seconds per segment. Longer audio files are automatically split.
- Reranking required: Multimodal collections require
rerank=true. Text-only collections are unaffected. - Latency: Multimodal queries take ~1-2 seconds (text embedding + media search + reranking). Text-only queries are unchanged. We are continuously optimizing query latency to make search as fast as possible without compromising accuracy.